
GEO Writing Made My 92 Podcast Episodes Clearer and More Discoverable
Why many discoverability problems are actually interpretation problems

Most discoverability problems aren’t actually content problems. They’re interpretation problems.
Over the past few months, I retitled 92 older podcast episodes from my interview podcast, Expats, Geopats, Etc (rebranded from Geopats Abroad), using ChatGPT, Claude, transcripts, and spreadsheets.
At first, I thought I was working on podcast SEO. Technically, I was. But somewhere in the middle of the process, I realized something much bigger was happening. Platform algorithms and humans both struggle when content is difficult to interpret quickly and I was clearing up my podcast supporting text to make the meaning understandable for both at the same time. Not some words for the machines and some for the humans but the same textual clarity for both. At the same time.
This online text lack of clarity problem isn’t only a podcasting barrier. The same issue affects newsletters, YouTube videos, blog posts, online courses, LinkedIn posts, websites for personal brands, and large content archives across the internet. Valuable work often becomes difficult to discover because the text surrounding it doesn’t clearly explain what the content is, who it’s for, or why it matters quickly enough.
This is one thing about GEO (Generative Engine Optimization) that I personally love. GEO writing pushes creators to structure ideas in ways that are easier for both humans and AI systems to interpret, summarize, retrieve, and recommend.
This matters for podcasters, newsletter writers, YouTubers, educators, consultants, and anyone managing large conversational content archives online.
Key Takeaways
Many discoverability problems are actually interpretation problems.
Platform algorithms rely heavily on titles, metadata, transcripts, and contextual language.
Humans scanning quickly online behave more similarly to algorithms than many people realize.
GEO-focused writing prioritizes immediate interpretability for both humans and AI systems.
AI-assisted optimization works best when paired with strong human editorial judgment.
You can read the original case study for more details.
In Part 1, I focused more on the AI workflow itself, the retitling process, and why human expertise still mattered inside the system. Now that it’s been two months since the concentrated retitle phase, I can finally talk about what changed afterward and what the project revealed about discoverability and communication.
Why Podcast Episode Titles Start Out Weak: A Moment In Time problem
One of the challenges with conversational content is that it’s often not labeled for clarity from the beginning. The ideas may still be useful. The conversations may still contain emotionally resonant stories and exactly the kinds of experiences people are actively searching for. But because episode production is often weekly, there’s more of a focus on getting the episode out than in making sure it’s text is strong for search discoverability. And revising episode titles is a rare task in the space.
This was part of what happened with Expats, Geopats, Etc. The show focused on identity, culture shock, language learning, belonging, and life abroad. Many of the conversations still held up surprisingly well years later. The problem wasn’t the content itself, it was that many of the original titles reflected what the conversation meant to me while recording it instead of what an outside listener could immediately understand.
Example 1: Incomplete summary title
Original Title: “Pet culture shock in China?”
Revised Title: “Living Abroad in China: Culture, Dogs, and Expat Life in Shanghai”
Where example 1 focused too much on one part of the interview, example 2 tried to include so much of the conversation that it conveys almost no meaning at all. It’s too vague.
Example 2: Vague title
Original Title: “First China culture shocks for an American expat”
Revised Title: “Expat Life in Shanghai: What Americans Get Wrong About Moving to China”
The interesting part wasn’t simply that the titles became longer. They became easier to interpret. The updated versions introduced geographic context earlier, clarified emotional framing faster, and gave both humans and algorithms more contextual information immediately. Instead of emphasizing one isolated moment from the episode, the revised titles communicated the broader emotional and thematic direction of the entire conversation.
That shift transformed the archive from a collection of disconnected episodes into a more coherent library of evergreen stories.
Why Humans and Algorithms Both Need Clear Context
One thing many people misunderstand about algorithms is that they can’t experience content the way humans do. A listener can sit with ambiguity for a while. Humans are surprisingly good at slowly piecing together meaning once they’re emotionally invested in a conversation. Algorithms aren’t.
Algorithms can’t feel emotional tension in someone’s voice. They can’t recognize subtle narrative shifts buried thirty minutes into a discussion. They rely heavily on the interpretive scaffolding surrounding the content itself:
titles
descriptions
transcripts
metadata
surrounding contextual language
Humans scanning quickly online often behave similarly.
When someone scrolls through a podcast app, LinkedIn feed, YouTube homepage, newsletter inbox, or search results page, they aren’t carefully analyzing every word. They’re making extremely fast interpretation decisions:
What’s this?
Who’s this for?
Why should I care?
What emotional experience or problem does this connect to?
Is this relevant to me right now?
The clearer the communication becomes, the easier those decisions become. That applies to both humans and platforms.
GEO Writing Prioritizes Immediate Interpretability
This experiment reinforced something I increasingly believe about GEO-focused writing.
GEO writing prioritizes immediate interpretability for both humans and AI systems. It pushes creators to communicate value earlier instead of hiding key information behind ambiguity, cleverness, or delayed reveals. It also encourages stronger contextual framing so platforms and AI retrieval systems can more accurately understand what a piece of content is offering. That doesn’t mean flattening personality or creativity. It means reducing unnecessary interpretation friction.
The strongest revised titles consistently introduced several things earlier:
geographic context
emotional tension
identity framing
listener-facing value
conversational stakes
Over time, the archive itself started developing stronger structural coherence, even though the conversations themselves never changed. The interpretation layer changed. I wasn’t rewriting history or changing the meaning of the episodes. I was restructuring how eight years of conversations communicated their value externally.
This is happening everywhere online right now. Many people still create genuinely valuable work but package it using language that only makes sense from inside the experience itself. The creator understands the significance immediately because they lived it. Outside audiences don’t have that context. Platform algorithms certainly don’t.
My old titles weren’t terrible, and the revised versions aren’t magically perfect now. Communication exists on a spectrum of interpretability. The changes simply moved these episodes closer to the kinds of language, framing, and contextual signals that potential listeners were already searching for.
The 5 Questions I Used to Retitle 92 Podcast Episodes
Eventually, the process became much more editorial than technical. Most of the work involved reducing confusion rather than adding marketing language.
These became the five core questions guiding the retitle process:
What’s this episode actually about emotionally?
What contextual information is missing?
What would a stranger understand from this title alone?
What language creates unnecessary ambiguity?
What phrasing makes the emotional stakes easier to perceive?
Those questions mattered far more than keyword density. In many cases, the strongest titles emerged through multiple rounds of iteration rather than from a single AI prompt. The process reinforced something I keep seeing across in my AI cowriting sessions. The quality of the outcome depends heavily on the human ability to recognize meaning, nuance, emotional framing, and contextual gaps.
AI helped me explore possibilities faster. Human editorial judgment shaped which possibilities actually communicated clearly.
How AI and Human Editorial Judgment Worked Together
LLMs like Claude and ChatGPT became useful because they accelerated restructuring, comparison, and reframing.
I could quickly test:
geographic emphasis
emotional emphasis
curiosity framing
search phrasing
audience clarity
interpretability
But the final judgment remained deeply human because communication is contextual.
The quality of the outcome depended heavily on human recognition of:
meaning
emotional framing
nuance
audience expectations
contextual gaps
AI helped me explore possibilities faster. Human editorial judgment determined which possibilities actually communicated clearly.
The strongest titles usually emerged through multiple rounds of iteration rather than from a single prompt. That reinforced something I keep seeing across AI-related workflows more generally. AI works best as a collaborative analytical system rather than an autonomous creator.
It’s important to note that even though LLMs helped me experiment with these titles faster, I didn’t save time using AI. If anything, it added more options to the titles than I would have come up with myself. I had to think longer and deeper about the choices I was making. This made the changes richer and more meaningful but not quick. Each episode title rewrite took 30 to 45 minutes, including time to marinate in options and ideas before making a final decision or edit.
What Changed After Retitling 92 Podcast Episodes
The podcast experienced a noticeable growth spurt after the concentrated retitle phase. Here’s a snapshot of the podcast downloads before and after the change.
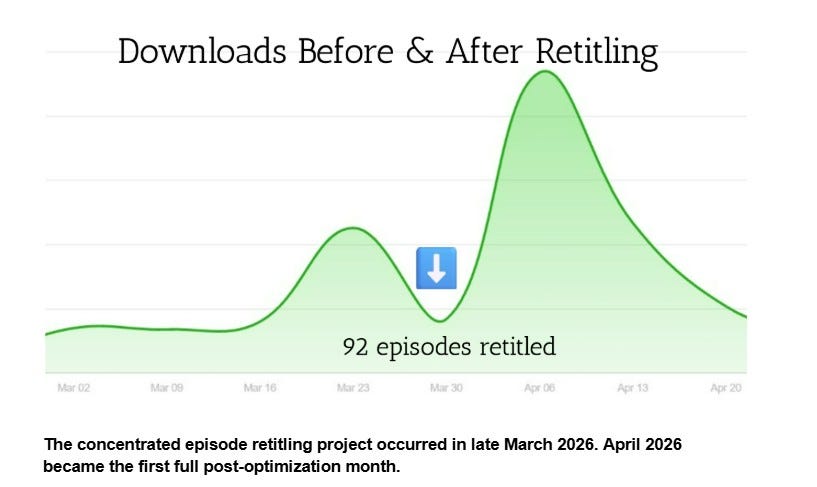
Importantly:
no new episodes were released
no major promotional campaign occurred
no additional metadata work was introduced during that period
I intentionally paused additional optimization efforts because I wanted to observe the impact of title restructuring itself before introducing more variables. At the same time, I don’t want to oversimplify causation.
Interest in moving abroad, especially from the United States, also appeared to be increasing during that period. Platform algorithms and audience behavior are complex. The retitle project didn’t happen in a vacuum. Still, the timing was strong enough to convince me that metadata interpretation matters far more than many creators realize.
The numerical growth wasn’t the most interesting outcome. The more interesting outcome was structural clarity. Older episodes became easier to navigate. The archive became easier to share confidently. The themes became easier to recognize quickly. The overall catalog started feeling more coherent.
The content itself didn’t suddenly become more intelligent. It became easier to understand.
It became the library I had originally wanted it to be. A searchable library of stories about identity, belonging, language, and the emotional realities of living outside your home country.
I break down the full retitling workflow, title changes, and analytics in the original case study here.
Why This Matters Beyond Podcasting
This experiment reinforced something much larger than podcast optimization.
Many discoverability problems online are actually communication clarity problems. Sometimes the issue isn’t that the work lacks value. The issue is that humans and platforms alike struggle to interpret what the work is actually offering quickly enough.
That’s a very different problem. We’re probably going to spend the next several years talking about this much more seriously as AI-assisted algorithms continue expanding across the internet. This is also one of the reasons GEO-focused writing matters. GEO isn’t just about trying to “rank” inside AI systems. At its best, it’s about reducing communication failures.
Clearer structure, answer-first framing, stronger contextual signals, extractable insights, and more explicit communication help both humans and AI systems understand content faster.
The more I worked through this retitle project, the more I realized that discoverability and communication clarity are becoming deeply connected online.
If you missed the original case study, you can read it here.
If this kind of AI-assisted communication thinking interests you, join us weekly for deep dives like this.
This newsletter is where I explore what these systems actually do well, where they fail, and how humans can work with them without flattening everything into generic internet language.
And if you know someone working with podcasts, archives, newsletters, YouTube channels, or large conversational content libraries, feel free to share this post with them.
Until next week,
Steph